Following on from the previous post in the Adventures with CBStreams series, Adventures with CBStreams - API Transformations, today I wanted show you an example I have used in the past to use streams to effectively group your data.
I was working on a legacy application last year, and one part of the code was using a cfoutput loop over a query recordset, applying the group attribute to manage processes for the data based upon a certain value in the query.
To mock up something similar, I have created the following dummy query object:
The output is a beautiful query of delicious things.
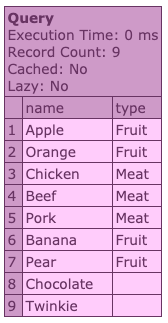
You can see that the items contained within have certain types, with which we can group them.
In the application I was working on, based upon the grouped items within the query loop, other actions were happening. For example, if the item was fruit it could make a second call to the database to pull out specific information for that particular fruit, or it could make an API request to a service to find information about the specific meat.
You get the idea, I hope.
There was a lot of code, all tag-based, that handled this. It wasn’t easy to read, and as a result wasn’t easy to keep under control.
It was also not as performant as it could be.
Use streams to group your data
Let’s take a look at an example of how this tag-based code was performing the grouping process. Bear in mind that there was a lot more going on within the actual code I was working on. This is a streamlined example.
Looping over the qFood query and using the group attribute to group by type, we first need to ensure that we have detected any items without a type value set, and set them to Other.
We then check to see if the key exists in our destination structure, and if not add it in.
Finally, we can loop over each grouped type item and insert it into the correct array within the structure.
The output would look something like this:
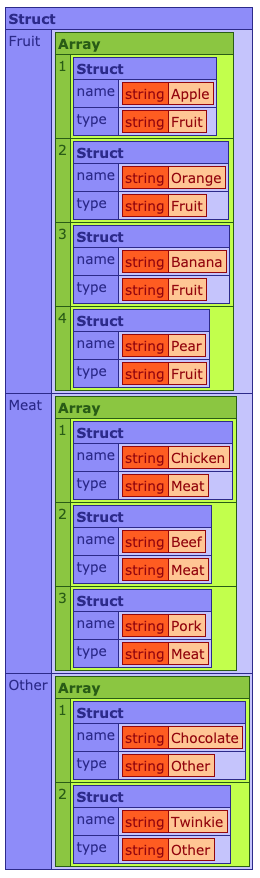
It works, it does the job, but this particular code I was working on was doing some very heavy lifting and additional calls to other resources to update data, transform structs and return what it needed as part of the resulting grouped object. It also had the potential to deal with A LOT of items within the loop, and so was quite intensive in terms of process time and response.
This is where cbstreams came into effect. By managing the grouping through Java streams, I was also able to harness the asynchronous functionality by using the parallel() method.
The above code loops over the entire query using the rangeClosed() method, from the first row to the end row.
We get each row from the query as a struct using the first map() function. This struct is then fed through the pipeline into the final collectGroupingBy() method.
This cbstreams method is a wrapper for the underlying Java streams functionality which lets you group by a single column value. A classification function is applied to each element of the stream. The value returned by that function is used as a key to the map that we get from the collectGroupingBy() collector. In our case, the type property of each record.
Inside of collectGroupingBy(), I was able to group the structs into arrays using the type value for each item, resulting in a nicely grouped HashMap containing our data.
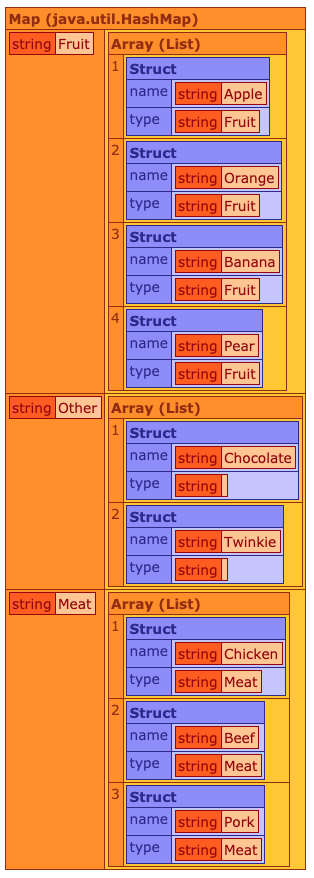
As I’d mentioned, there was a lot of heavy lifting going on in the original code, and as we’ve seen with the API Transformations post, we can easily manage additional processes as part of the stream pipeline.
To update the example, let’s transform some of the data coming in. In my rather crude example, we’re just adding a UUID value to each record, but it could be anything, including external calls to an API.
The important part here is to ensure that whatever we return from the second map() function contains the type property, as we are using that as the collector in the final grouping method.
The Java streams are able to handle this easily, as you may expect, and the resulting output is now a transformed group of data, taking the original query row values and updating or appending, however needed.

That’s it for this example. If you have any questions, please let me know.